
Azure Databricksを中心としたデータ基盤への刷新。データをグループ会社横断で活用し、価値創出を行う施策
イオン株式会社のAI・Data系部署に所属しデータエンジニアをしている星野と申します。2023年8月より部署のデータ基盤をAzure Databricksを中心としたものへ刷新しました。本記事ではこれにより得られた恩恵をみていきます。
イオンのデータ
まず、イオンのデータについて紹介させてください。
イオングループはM&Aで大きくなってきたという背景があります。イオングループ事業・企業紹介をご覧いただくと、身近な会社もイオングループの一員ということに驚かれるかもしれません。
データについても、この背景により、現状は各企業がデータ基盤を持っている状態です。ほとんどが小売業を営んでいるため、「商品」や「POS」など扱うデータは似てはいるものの、データ構造・アーキテクチャ・組織文化などは全く異なり多種多様です。
所属について
次に、私の所属について簡単に述べます。
前述の背景のもと「各所に点在するイオンのデータを横断的に活用し、価値創出を行う」ことを目的に2021年に発足したのが私の所属する部署です。グループ各社と協力し、点在するデータの収集・活用施策のプロトタイピングや導入支援等を行うR&D的な役割を担います。
より具体的には「イオンのデータとデータサイエンスを掛け合わせ、データによる新たな価値創出を行う」ことがミッションであり、商品・POSデータを利用した商品価格の最適化・需要予測や、生成AIによる商品POPの作成などに取り組んでいます。
データ関連ロールとしては、データサイエンティストとデータエンジニアの2種が存在し、各々の構成と役割は以下です。
- データサイエンティスト(約10名):データサイエンスの実施、グループ会社への成果物導入支援が責務
- データエンジニア(筆者含め3名):データ収集、データ整備、データ基盤の改善が責務
データ基盤について
本題のデータ基盤をみていきます。
今までの総括的内容ですが、弊部のデータ基盤の役割は以下であり、主要ユーザーは部署内のデータサイエンティスト・データエンジニアです。
- グループ会社に点在するデータを継続的に収集すること
- データエンジニアリング・データサイエンスの役割を全うすること
以前のデータ基盤と課題
データ基盤として、発足当初から以下の構成を採用していました。
- Azure Data Lake Storage Gen2:オブジェクトストレージ
- Azure Synapse Analytics:データエンジニアリング、データサイエンスの前処理
- Azure VM:データサイエンス(データサイエンティストが1人n台保有)
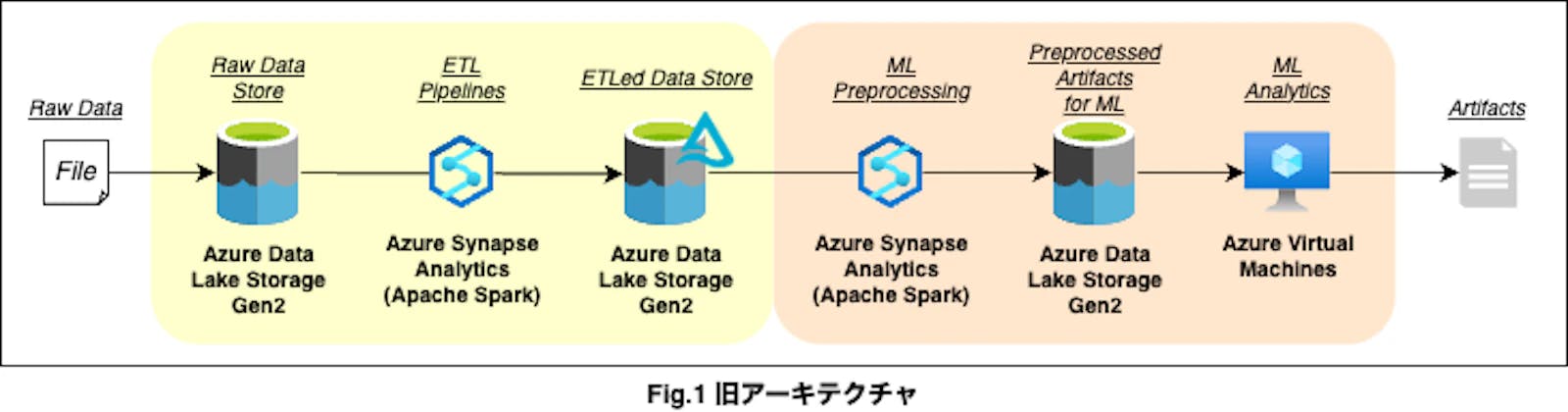
いくつかあった課題のうち、Azure VMでの作業の不透明性が一番大きなものでした。すべてが使用者依存であったため、プロジェクトの長期化と拡大によって引き継ぎや複数人進行が必要になるにつれ、この問題が顕在化しました。以下が顕在化した問題の一例です。
- 構成管理
- 他の人が再現できない環境
- Azure VMでのデータ処理
- 処理がデータ基盤に還元されず、再利用できないデータ
- ワークフロー管理 / MLOps
- 手動運用派の場当たり的な運用に起因した再現できない成果物
これらを解決するために、Azure Databricksを導入しました。
Azure Databricksを中心としたデータ基盤
- Azure Data Lake Storage Gen2:オブジェクトストレージ
- Azure Databricks:データエンジニアリング・データサイエンス
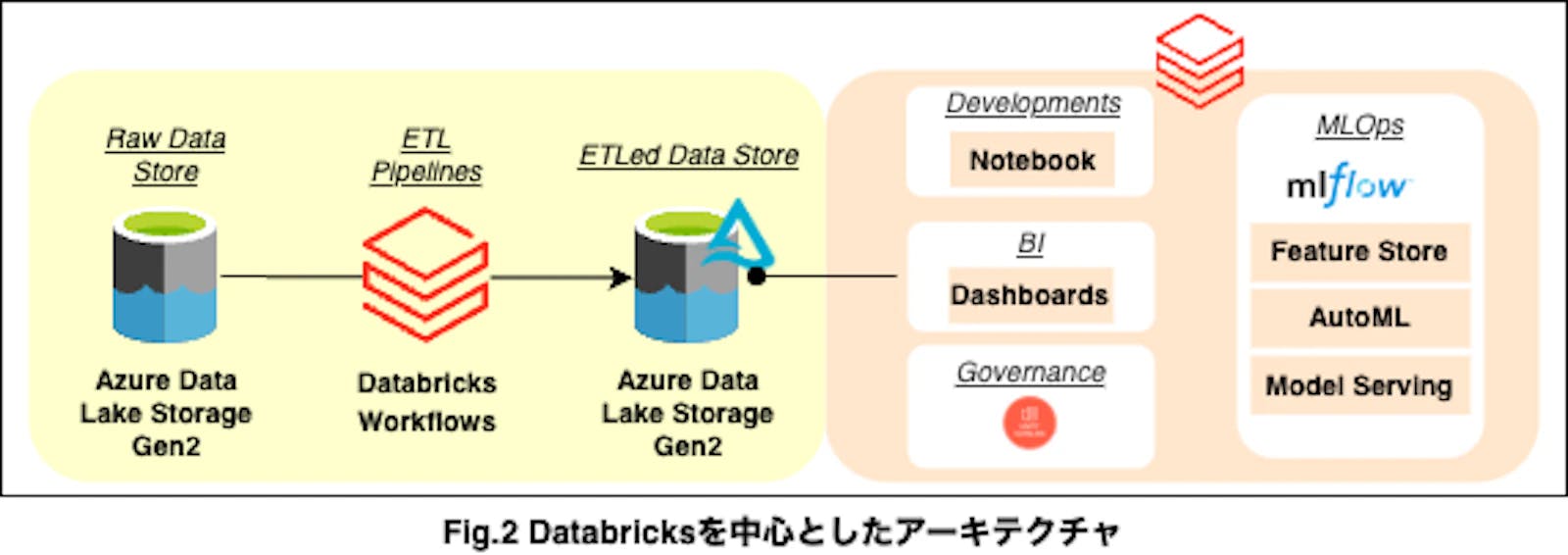
そしてこれらの問題は以下のように解決しています。
- IaC(Infrastructure as Code)による構成管理。IaCになじみがなく、各種リソースをGUIで作成したとしても構成をJSON出力可能
- データの処理をDatabricksに集約し、部署内でのデータサイロを抑止
- フルマネージドなワークフローオーケストレーションであるDatabricks WorkflowsとマネージドMLflow
上記に加え、以下の効果も得ています。
- Compute Policyによって敷設したガードレールの範囲内であれば、自由にComputeをスケールアップ・スケールアウト可とし、セルフサービス化
- スポットインスタンスと事前購入を活用し、金銭コストを抑制
実開発においても、ノートブックの使用感の良さやAIアシスタント機能によるコードの生成・デバッグ補助機能のおかげで、データエンジニアリング、データサイエンス双方で開発のアジリティ向上を感じています。
これらの恩恵にあずかれたことから、Databricksへのリプレースは正解だったと考えています。
データコラボレーション
データエンジニアリング、データサイエンスの観点に限らず、グループ各社とのデータコラボレーションの観点でもDatabricks導入の恩恵を受けつつあります。
まず、グループ会社からのデータ収集について、Databricksの導入により、Unity Catalogを通じたLakehouse Federationの機能で、グループ会社のデータストアのデータを直接参照できるようになりました。以前は、ファイル転送によるデータ連携を行っていたのですが、さまざまな事前手続きに時間がかかり、実際にデータを受領するのに1、2カ月を要することが珍しくありませんでした。しかし、Lakehouse Federationにより、このリードタイムを削減できるのは大きな恩恵です。
また、データサイエンス成果物についても、Unity CatalogのアクセスコントロールやDelta Sharingを通して、グループ各社へ直接提供できるようになりました。実際に、グループ各社のユーザーへ特定のノートブックを触る権限を与え、成果物を直接触ってもらっています。従来の、グループ会社へ成果物を定期的にレポーティングという方式に比べ、レポート作成の手間を省けるメリットがあるほか、動くものをユーザーに触ってもらうことでフィードバックが得やすくなる効果も狙っています。
さらに、実際に利用されているかどうかをアクセスログで確認可能なため、利用されていないようであれば理由をヒアリングするというアクションも取れるようになりました。このように成果物のフィードバックサイクルを回せるようになった効果もあります。
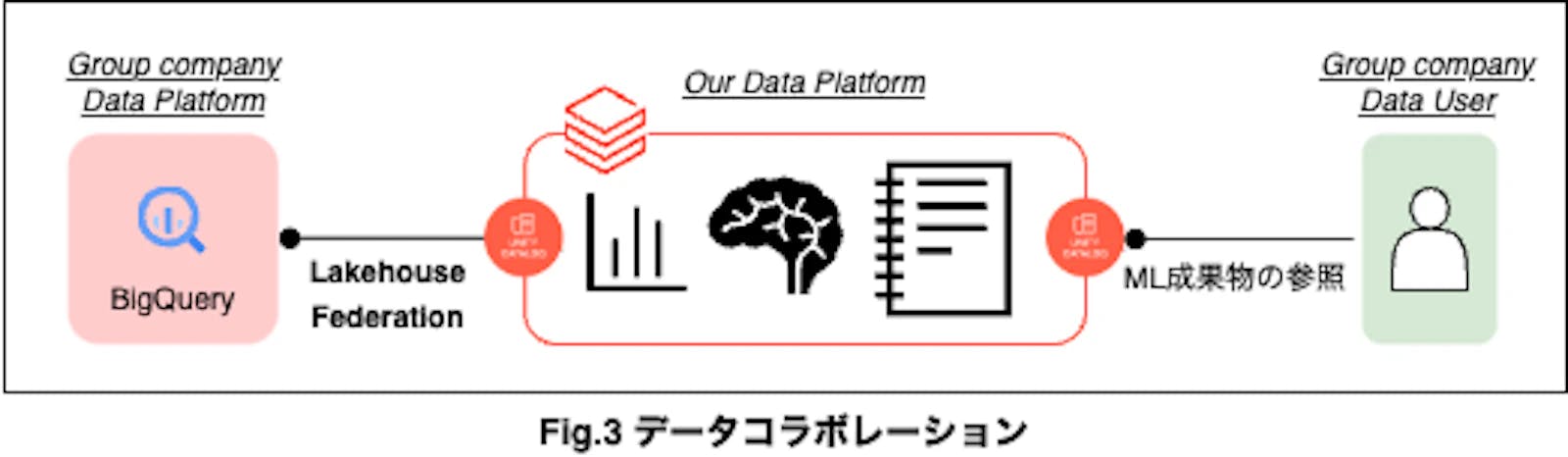
リードタイムの削減、フィードバックサイクルの改善により、仮説検証スピードを高めることができるようになりました。一見地味ですが、価値創出のために仮説検証を繰り返す必要がある我々にとって、確実に効いてくるものなので、やはりDatabricks導入効果は大きいと考えます。
まとめと今後の展望
部署内のデータ基盤をDatabricksにリプレースしたことにより得られた恩恵を紹介しました。データ基盤でお悩みを抱える方の一助となれば幸いです。
今後の展望として、データエンジニアリング・データサイエンスについては、Databricksの機能リリースはもちろん、周辺技術についても良いものは積極的に取り入れていこうと考えています(この分野、エコシステムの進化がとても速くキャッチアップは大変ではありますが……)。
また、データコラボレーションについて、紹介したDatabricksの機能を利用した連携を始めたのはごく最近、適用範囲もごく一部で、データ収集・成果物提供の双方とも従前の方法が大半です。データによる価値創出をより早く行うために、データコラボレーションの機能をフル活用していきたいと考えていますが、それにはグループ各社の協力が不可欠です。グループ各社と気持ちよくコラボレーションするための近道はないので、地道に実績を積み重ねていく所存です。
イオングループユーザーの皆さまへ一日でも早く価値還元ができるよう、引き続き創意工夫してまいりますのでよろしくお願いいたします。
執筆協力:土沢誉太
編集:中薗昴
提供:株式会社Haul
無料で技術スタックを掲載する
このページをシェア
このページをシェア
ニュースレター購読
what we use の新機能情報や掲載企業追加情報などをお送りします。


技術スタック・ツールのデータベースサービス
© 2026 HRBrain, Inc.
技術スタック・ツールのデータベースサービス
© 2026 HRBrain, Inc.