
技術的負債の解消のためには、“経営層との合意形成”が不可欠。DIGGLE社に学ぶ開発体制構築の秘訣
DIGGLE株式会社でエンジニアリングマネージャーをしている岡崎と申します。普段はエンジニアチーム全体のマネジメントを担いつつ、開発業務も行っています。DIGGLEは予実管理クラウドサービス「DIGGLE(ディグル)」を提供するスタートアップであり、「RubyKaigi 2023」のスポンサーを担うなどテクノロジーやそのコミュニティへの投資を積極的に行っています。本記事ではDIGGLEのエンジニアチームが、どのように技術的負債解消を行っているかについてご紹介します。
工数の何%を負債解消に充てるかを四半期ごとに経営と合意する
技術的負債解消は、エンジニアチーム単体でやり切るにも限界があり、経営陣の理解を得ることが重要です。弊社はCTOが共同創業者であるため、エンジニアの意見が経営陣へダイレクトに届き、経営陣の技術に対する理解度が非常に高いのが特徴となっています。CTOから技術的負債がビジネスに及ぼす影響を経営陣に説明することで、技術的負債解消の重要性を経営陣も理解し、技術的負債解消に対して一定の工数を割くことができる状態になっています。
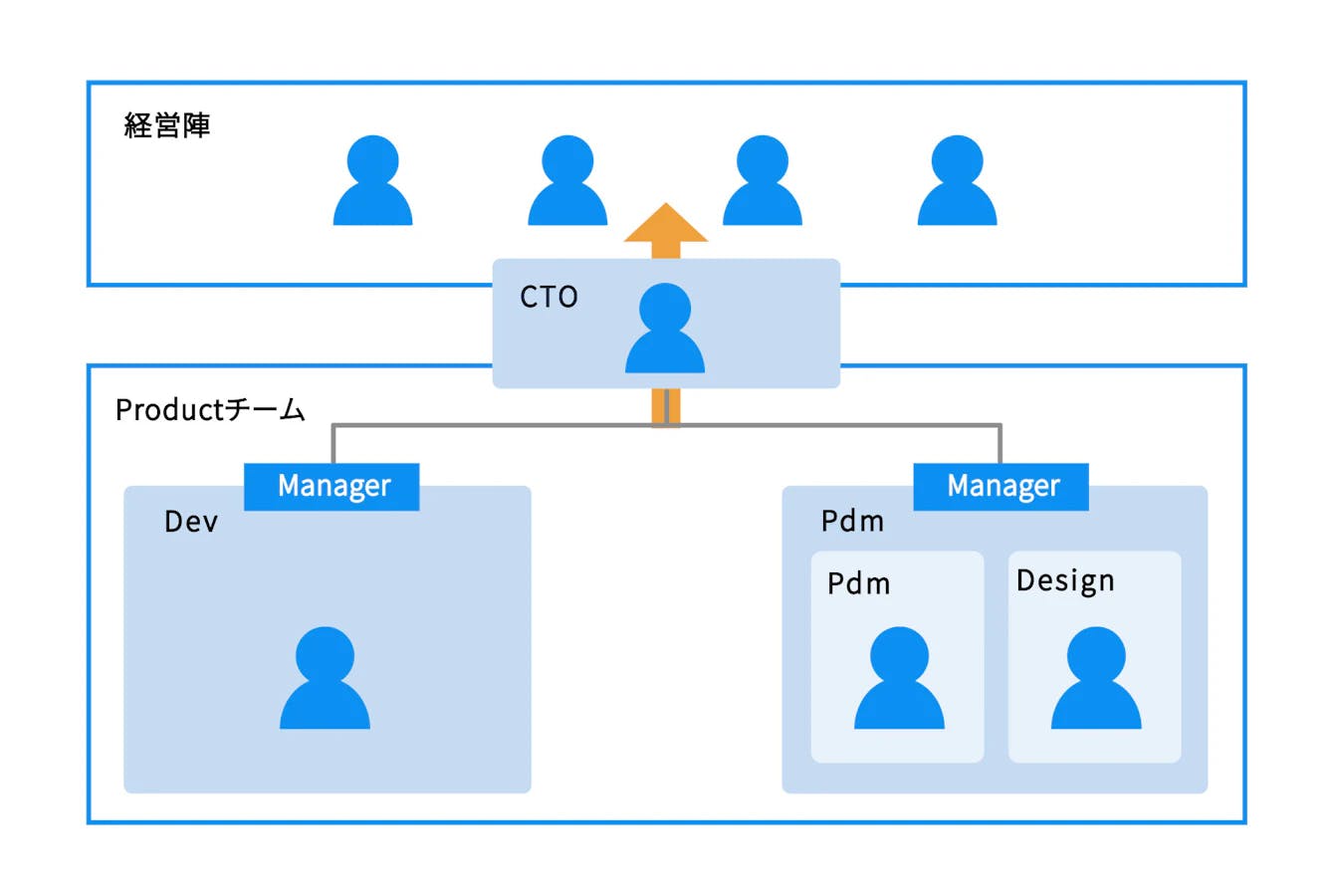
実際にどの程度の工数を割くかについては、四半期ごとに、私とCTOで技術的負債解消に割り当てられる工数の目安を相談して決めています(おおよそ20%程度に収まることが多いです)。
このような仕組みにすることで、技術的負債を会社全体の関心事として捉え対応することが可能となり、「日々の作業が忙しくて技術的負債解消を行うことができない」という状態に陥らないようにしています。
実際に、技術的負債解消の中で解決した問題を弊社のエンジニアブログで取り上げていますのでご紹介します。
Ruby のバージョンを 3.1 系から 3.2 系にアップデートしたら Ruby on Rails アプリの動きが変わったのを解決した話
DIGGLEでは経営陣に技術に対する理解があるためこうした体制を実現できていますが、読者の中には「なかなか経営陣に技術的負債解消の重要性を理解してもらえない」という環境の方もいらっしゃるかもしれません。
その場合は、臨機応変に可能な限り権限が高い方(CTO、部長、リーダーなど)と技術的負債解消の重要性を共有し、組織やチームで継続的に技術的負債に対応できるように働きかけていくことから始めると良いと思います。
そして、技術的負債の解消により得た実績(工数が削減した、バグが減少したなど)を収集することで、技術的負債解消がどのような好影響を与えたかを定量的に測れる仕組みを作ることが肝要となります。そうして計測した数値を基に、経営陣と根気強く対話をし、ゆくゆくは会社全体で技術的負債に立ち向かえる環境にしていきましょう。
参考までに、弊社で計測している数値をご紹介します。弊社では以下の数値などを四半期ごとに計測し、CTOを含む開発チーム全体で状況を共有する仕組みを作っています。
- どの作業にどのくらいの工数が掛かったか(新規機能開発 / 既存機能改善 / 技術的負債解消 など)
- 本番環境でどのようなバグが発生したのか(インシデント / デザイン崩れ / 軽微なバグ など)
- 上記のバグ対応でどのくらいの工数が掛かったか
開発作業の終わりにリファクタリングを行う文化
弊社のエンジニアチームには、開発作業が終わったタイミングでリファクタリングを行う文化があります。
これは私が社員3人目として入社した2019年当時から存在しているのですが、開発作業が終わってPull Requestを投げる前に、リファクタリング用のタスクを切って、コードの整理やテストコードのバリエーション追加などの対応を各エンジニアの裁量で行う文化です。
これにより、常日頃から各エンジニアが個人レベルで意識を持って作業し、「そもそも技術的負債がたまりにくい土壌」が作られています。
TODOやFIXMEを放置しない仕組み
エンジニアの皆さんは共感してくださると思うのですが、ついつい書いておきたくなってしまうTODOやFIXMEは、時間が経って数が多くなってくると以下のような問題が起こります。
- 多過ぎてどこから手をつけてよいかわからず、結局放置する
- 時間が経ち過ぎて、書いた本人すらどんな内容だったかを覚えていない
- コメント量が少なくて、そもそも何に対するTODO / FIXMEなのかがわからない
弊社では、これらの解決策として「TODOやFIXMEを書く場合はJIRAにタスクとして挙げ、TODOコメントにはJIRAのリンクを記載する」というルールを作っています。これにより、先ほどの問題点は以下のように解決することができます。
- 多過ぎてどこから手をつけてよいかわからず、結局放置する
→常日頃使っているJIRA上でタスクとして確認することが可能になる
- 時間が経ち過ぎて、書いた本人すらどんな内容だったかを覚えていない
- コメント量が少なくて、そもそも何に対するTODO / FIXMEなのかがわからない
→JIRAの本文に背景・内容を記載することで把握ができる
→バックログリファインメントで新規JIRAタスクを確認する際に、背景・内容が理解できるものになっているかチェックすることができる
上記運用に際して、Pull Requestレビュー時に目視でチェックすることは難しいため、TODOやFIXMEにJIRAリンクを付けていないとエラーになるようにCIを組んでいます。

参考までにrubocopのソースコードを添付します。
class TodoComment < RuboCop::Cop::Base
include RuboCop::Cop::RangeHelp
MESSAGE = 'Annotation comment, with keyword `%<keyword>s`, should have JIRA TASK (ex: DEV-N).'.freeze
def on_new_investigation
processed_source.comments.each_with_index do |comment, index|
next unless first_comment_line?(processed_source.comments, index) ||
inline_comment?(comment)
annotation = RuboCop::Cop::AnnotationComment.new(comment, keywords)
next unless annotation.annotation?
next if jira_task?(annotation)
register_offense(annotation)
end
end
private
def register_offense(annotation)
range = annotation_range(annotation)
add_offense(range, message: format(MESSAGE, keyword: annotation.keyword))
end
def first_comment_line?(comments, index)
index.zero? || comments[index - 1].loc.line < comments[index].loc.line - 1
end
def inline_comment?(comment)
!comment_line?(comment.loc.expression.source_line)
end
def annotation_range(annotation)
range_between(*annotation.bounds)
end
def jira_task?(annotation)
annotation.comment.text.match?(/DEV-\d+/)
end
def keywords
%w[TODO FIXME]
end
endライブラリのアップデートを、SaaSを使って自動で行う
弊社プロダクトは主にRuby on RailsとReactで構成しているのですが、gemやnpmなどのアップデートはdepfuというサービスを使って、自動でPull Requestを作成する仕組みにしています。
depfuで作成されたPull Requestについては、逐次対応するのは大変なので(後述のセキュリティアップデートは異なります)、3カ月に1回、エンジニアチーム全体で分担してdepfuが作成したPull Requestの確認と、必要に応じた修正をしています。
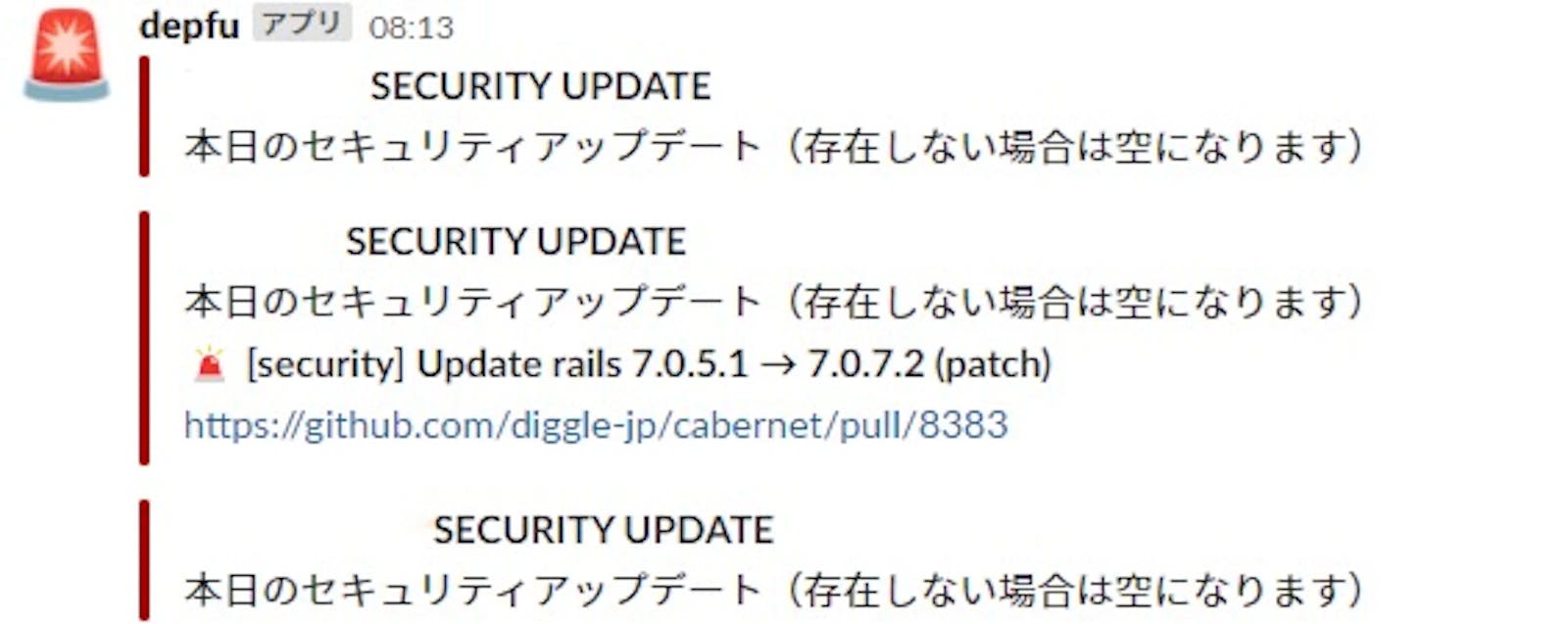
セキュリティアップデートについては、即対応が求められるものとなりますので、毎朝Slackに通知を飛ばします。アップデートがある場合は、デイリースクラムで担当者を割り当てて即日中にリリースするような仕組みとなっています。
OSのミドルウェアアップデートは週次で自動実行する
次にサーバーのOSミドルウェアのアップデートについてですが、弊社ではAWS Fargateを利用し、Docker imageを使ってリリースしていますので、Docker image内でのライブラリアップデートをどのように行っているかについてご説明します。
各サーバーが利用しているDocker imageに関しては、CIにより週次でライブラリのアップデートを行っており、各エンジニアが意識することなく、日々のデプロイを行うタイミングで最新のライブラリが自動適用されるようになっています(もちろん、試験環境で動作検証を実施してからリリースを行っています)。
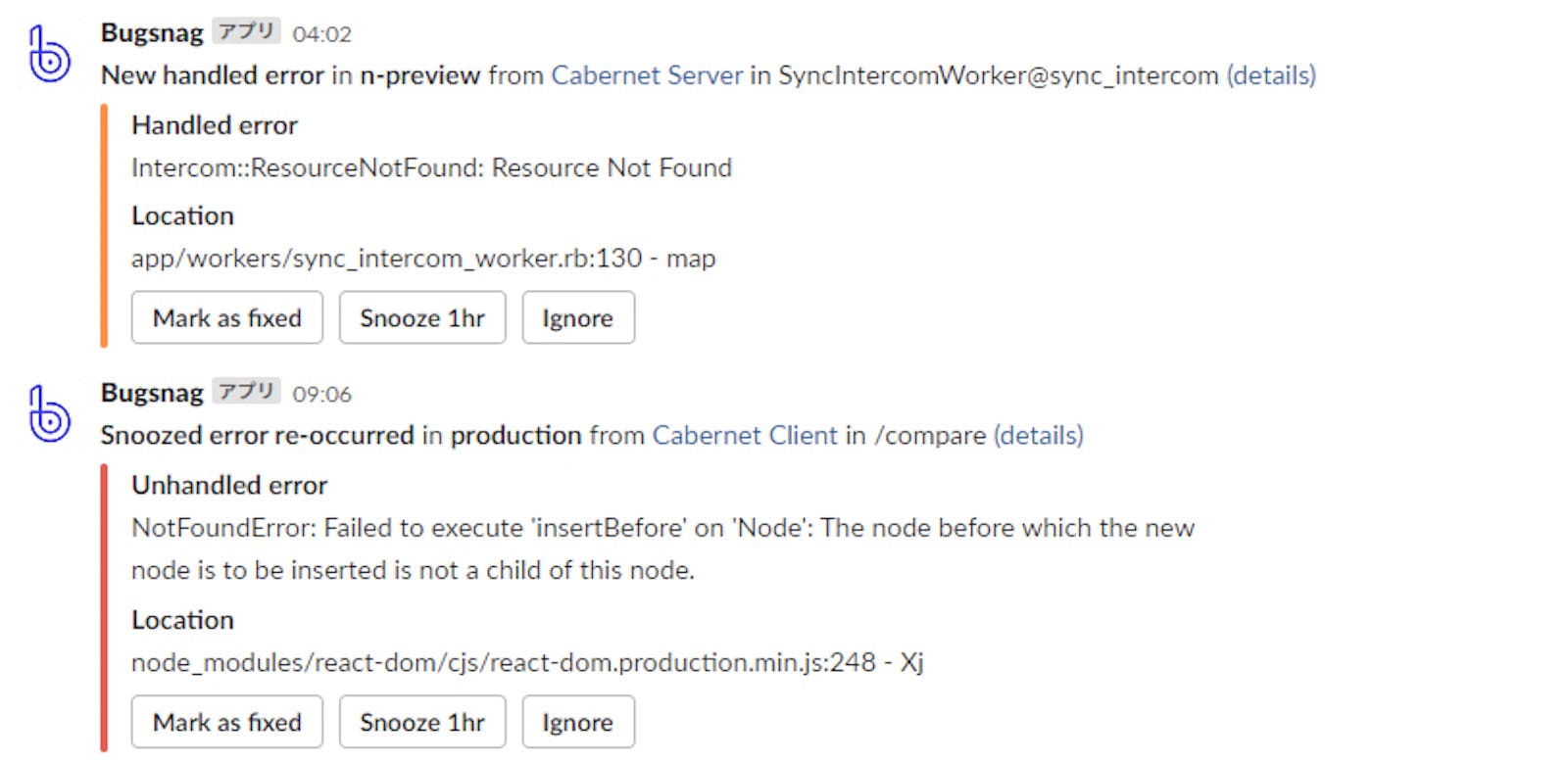
バグやSlow Queryを自動検知する
弊社ではBugsnagというサービスを使って、バグが起きた際にSlackへ通知を飛ばす仕組みを作っています。バグについては、営業時間内であれば即時、営業時間外であれば次の営業開始時に確認します。そして、この仕組みに相乗りする形で、Slow QueryについてもBugsnag経由でSlackに通知が飛ぶように設定しているので、同じフローで確認ができるようになっています。
積極的に自動化やシステム化をする
技術的負債解消に限ったことではありませんが、弊社では、前述したように自動化できるものは積極的に自動化しています。そして、自動化できないものについてもスクリプトを組むなど、なるべく人が行わなくて済むような仕組みを構築することを重要視しています。
自動化・スクリプト化する理由としては、工数削減と、ルール化・仕組み化の抑止の2つが挙げられます。
工数削減
こちらは想像しやすいと思いますが、自動化することにより手作業で実施するよりも工数を削減することができます。これにより、エンジニアの対応が必要な技術的負債解消に注力することが可能となります。
ルール化・仕組み化の抑止
定常的に何かをチェックしたり、対応したりする必要があるものについて、手作業で対応を行う場合、チェック表であったり、手順書であったりを作成することになると思います。そういった資料を用いつつ、ルールや仕組みを作って運用していくのですが、1つ2つであれば問題ないものも、数が多くなってくると把握が難しく、窮屈に感じるようになってしまいます。
そのため、弊社では可能なものについては自動化・スクリプト化し、ルールや仕組みをなるべく増やさないように心がけています。
上記2点の結果として、余分なところに貴重なエンジニアのリソースが割かれてしまうことを抑止できます。効率よく必要な箇所へ工数を注入することができるようになり、それが日々増えていく技術的負債に対する特効薬となります。
最後に
以上、DIGGLEにおける技術的負債解消方法を、いろいろな切り口でご紹介しました。
技術的負債はエンジニアを苦しめる問題であり、技術的負債が多ければ、それだけエンジニアの職場環境は悪いと言えます。そして逆に言えば、技術的負債の解消はエンジニアの職場環境改善の一助となります。
この記事が、読んでくださった方の職場環境改善の一助となることを願い、本記事を締めさせていただきます。
編集:中薗昴
提供:株式会社Haul
DIGGLE株式会社の技術スタックをチェック
無料で技術スタックを掲載する
このページをシェア


技術スタック・ツールのデータベースサービス
© 2026 HRBrain, Inc.
技術スタック・ツールのデータベースサービス
© 2026 HRBrain, Inc.