
データ連携の運用効率化の秘訣は「中間レイヤの抽象化」にあり。マネーフォワードを支えるデータ分析基盤の知見
株式会社マネーフォワードのCTO室副室長の松本と申します。主にデータエンジニアのチームのマネジメントを担当しています。本記事では執筆時点(2023年8月)のマネーフォワード内のデータ分析における業務やアーキテクチャについて説明します。
事業紹介
より具体的なイメージを持っていただくために、マネーフォワードはどのような事業を行っているかについてまずは説明します。法人向け・個人向け・金融機関向けという3つの事業領域を定義しており、法人向けは事業者の経理や人事労務などの作業効率化のためのバックオフィスSaaSの提供、個人向けは家計簿・資産管理アプリなどのPFMサービス、金融機関向けでは、金融機関の顧客への業務DXサービスやコンサルティングサービスなどを提供しています。
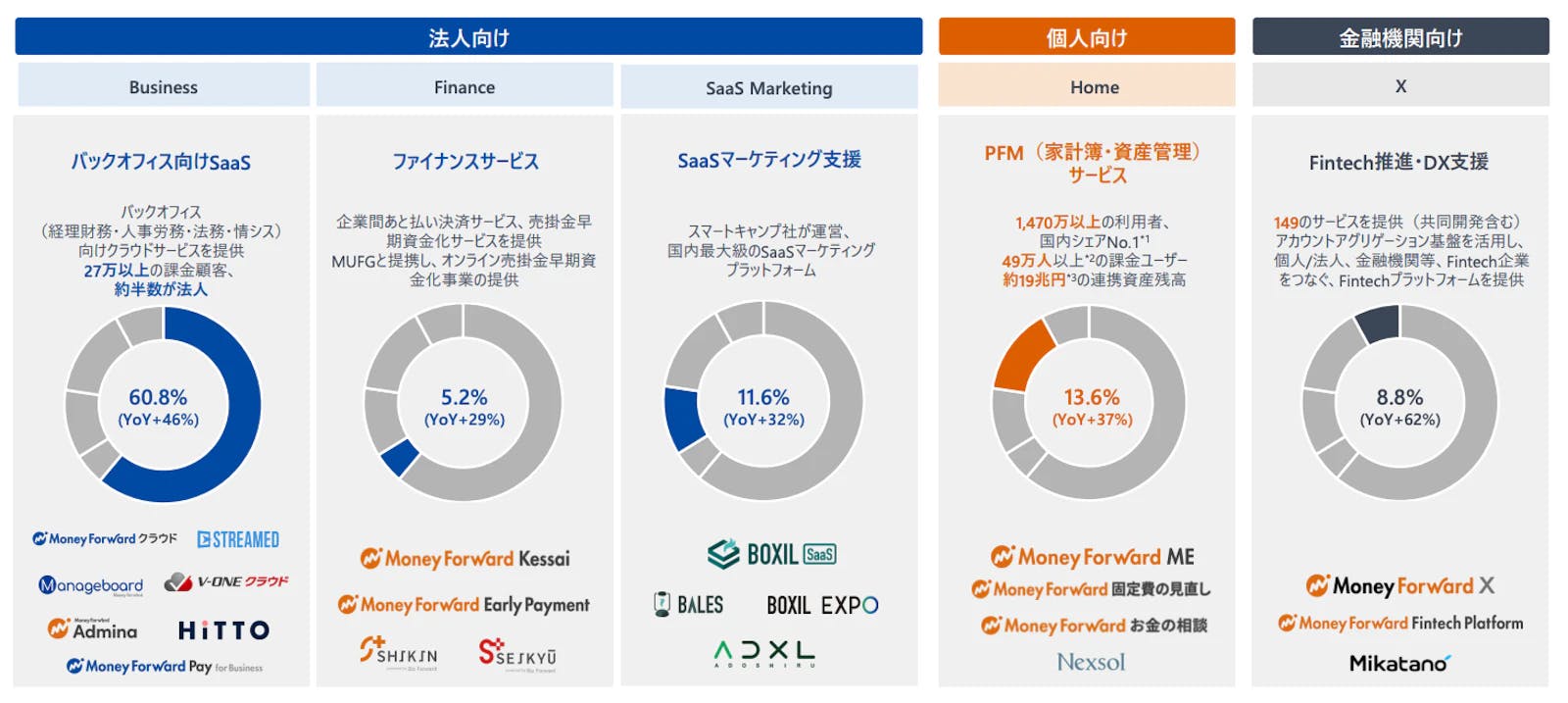
IR資料にもある通り、法人向け領域は売り上げの多くを占めており、特にデータ活用の社内ニーズも高まっている領域です。エンジニアチームも注力領域として日々改善を続けています。そのような背景から、本記事では法人向け領域でのデータ活用を中心に記載しています。
データ分析のワークロード
続いてデータ分析におけるワークロードについてです。データ分析のための業務と一口に言ってもさまざまな技術要素や知識が組み合わさって構成されています。生産性や専門性の観点から3つのプロセスに大別し、それぞれに業務プロセスや開発フローを定義し運用しています。
1.データ収集
1つ目はデータ収集プロセスです。データ分析に利用されるデータはプロダクトのデータベースだけではなく、利用しているSaaS・広告関連などのツール・行動ログなど多岐にわたります。通常これらのデータは1カ所に集約されていることはないため収集する仕組みを新たに構築する必要があり、収集する際には収集元の仕様やセキュリティ強度を理解した上で設計することが求められます。マネーフォワードのデータ分析環境は利用者が差異を意識せずに分析ができるよう連携先ごとに異なる仕様を吸収するために、スクラッチの仕組みやツールなどを組み合わせて構築しています。
2.データロード
2つ目はデータロードのプロセスです。こちらもユースケースによって同じデータソースに対してもさまざまな処理要求があります。用途によってリアルタイムに近いデータが必要である場合や、日次レポートや月次集計処理などの場合はそれぞれのタイミングに合わせる形でよいケースもあります。全てのデータを一律に処理すると仕組み上はシンプルですが、キャパシティやコストなどの問題を抱えることになるため、データロードにおいても異なった要件に対応できるよう複数の仕組みを用意しています。
3.データ利用・分析
3つ目は実際のデータ利用・分析のユースケースになります。データ収集とデータロードの工程を経て利用可能となったデータを用いて事業KPI管理のためのダッシュボードを構築したり、マーケティング施策の改善などビジネスのためにデータを活用したりすることなどが主な用途ですが、特別定額給付金が家計消費に与える影響に関する研究論文に利用された事例もあります。
アーキテクチャ構成と設計意図
上記を実現するためのアーキテクチャについて解説します。データの連携元としては代表的なものとしてRDB・SaaS・行動ログ・広告データの4つがあり、それぞれについて説明します。
多数のプロダクトから迅速にデータを集めるために
まずRDBとの連携ですが、マネーフォワードでは日々新たなプロダクトが生まれており、それぞれのチームが独立して意思決定を行い構築・運用しています。一方でデータ分析はさまざまな軸で行われるためシームレスに利用可能なことが求められます。それらを実現するために複数あるRDBのデータ変更をキャプチャし、集約した後に各環境へ配布するという方式をとっています。
直接的にデータロードをすることも可能ですが、一度同じ形式に変換する方式をとることにより、新規プロダクトの仕様差分を抽象化して分析可能なデータのデリバリー速度を向上させています。現状はこの方式に落ち着いているのですが、元々はそれぞれのプロダクトごとにデータ分析のパイプラインや環境が存在しており、開発や管理も煩雑な状態でした。そのため数年かけて集約に取り組みました。
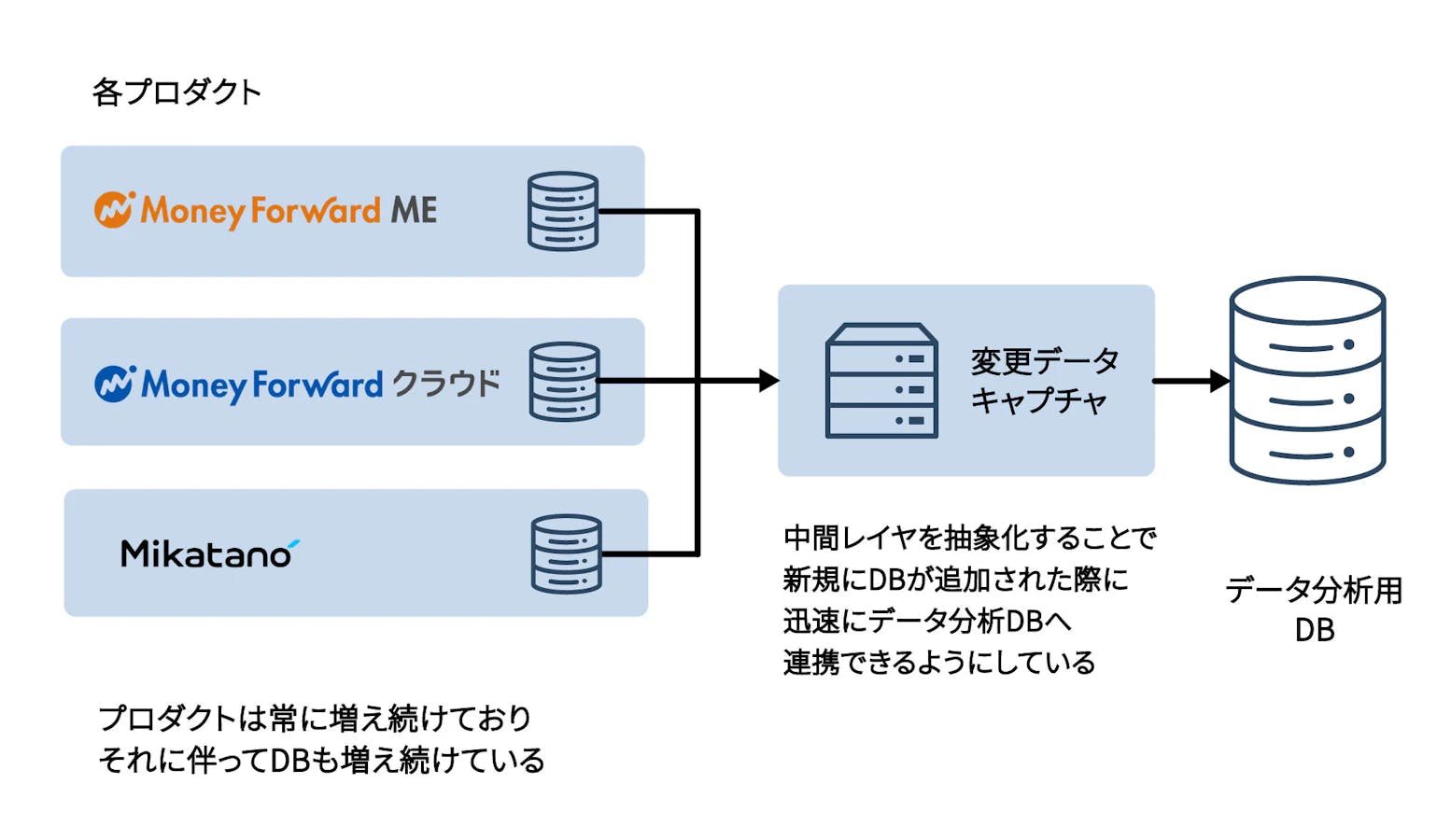
SaaSとのデータ連携においてボトルネックになりやすいのが仕様変更時の対応です。マネーフォワード内では業務効率化やビジネス成長を目的として各部署でさまざまなSaaSの導入検討や活用が進んでいます。一方でSaaSはそれぞれの仕様があり、安定して分析用途のデータを提供するためにはそれらの仕様変更に追随し続ける必要があります。
これらに対しては外部のETLツールを積極的に利用することで、社内のエンジニアがSaaSの個別仕様への追随を意識せずに済むようにしています。行動ログ・広告データもSaaSと同じく外部ソースなので、仕様変更を吸収するために外部のツールを利用しています。
一方で、ツールでは実現できない要件であるケースも多々あります。その場合は独自の実装をするケースがありますが、マネージドサービスと比較して技術面での負債化やメンテナンスコストの増大につながる懸念が大きいため、一定期間で再評価して継続すべきか否かの判断を行っています。
安全管理対策としての環境分離
またこれらのデータにはさまざまな情報が含まれています。情報の安全管理のために、各項目に情報レベルを定義・分類し、異なる環境へ格納するようにしています(言い換えると情報レベルごとに環境を分断しています)。各環境は参照できる情報が制限されていたり、エクスポートが制限されていたりとレベルに応じた安全対策がそれぞれなされています。
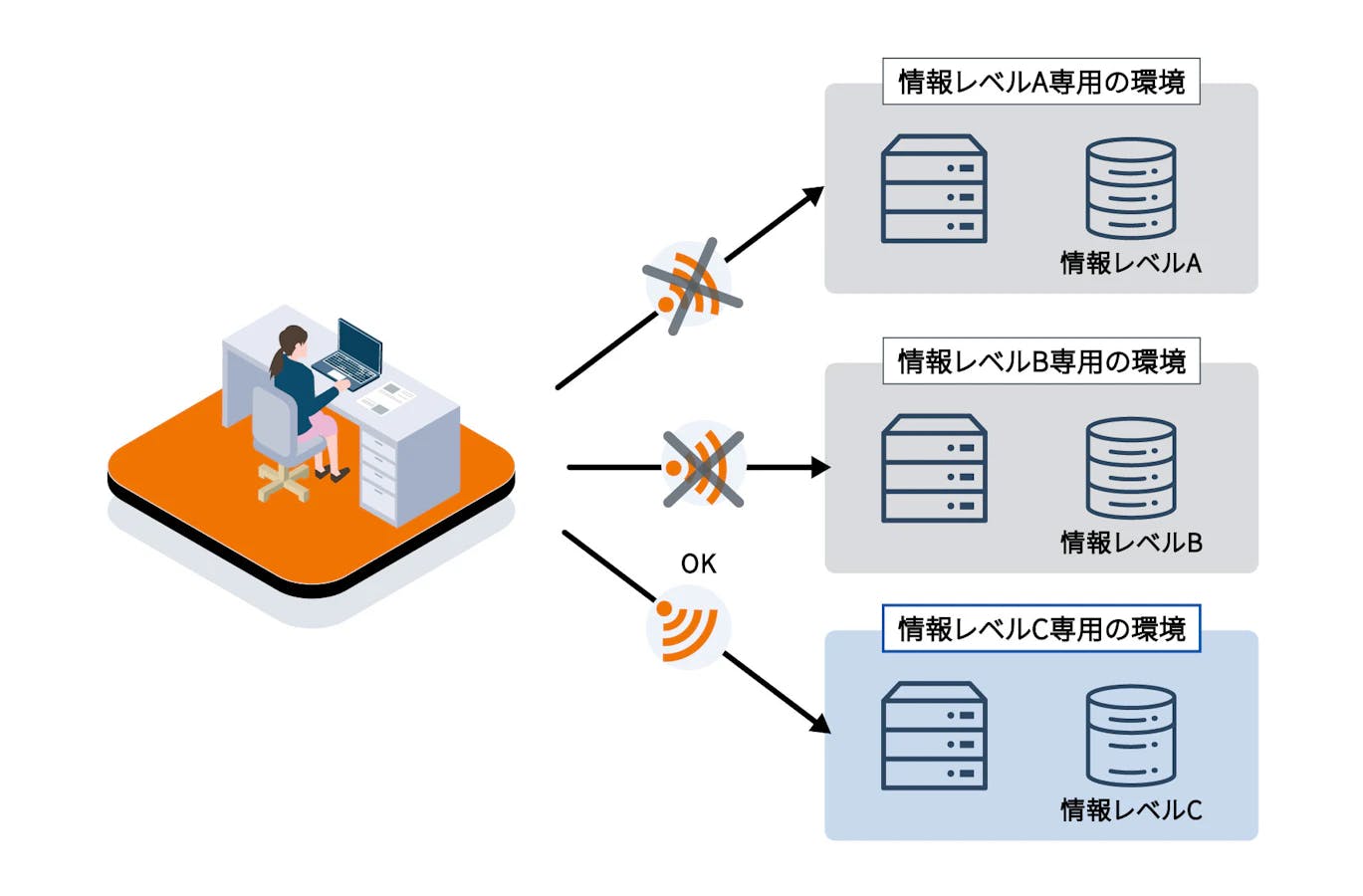
制約が多い環境は分析体験が悪化するため、分析者は分析の目的によって環境を使い分けています。そして、それぞれの環境に異なったレベルのデータが混入しないように自動で検知するための仕組みを構築し対処しています。
メタデータの重要性
これまでデータそのものの収集に関して説明しましたが、付帯情報(メタデータ)についても同様の課題を抱えています。つまり複数のプロダクトからデータを集約できても、それらのデータが何を意味するのかがわからなければデータとしての価値は低いですし、分析者が分析作業を中断して調査を行うのも合理的ではありません。
また、先に述べた通りマネーフォワードでは多くのプロダクトを運営しており、それぞれに開発チームが存在しています。つまり、多くの開発チーム・エンジニアが社内にいるということであり、問い合わせ先を確認するのもそれなりの作業量になります。これらの課題に対処するために独自で情報に対してメタデータを登録・更新できる仕組みを構築しています。分析者が一度調べた内容をこの仕組みに登録すれば、他の分析者もそれらの知見を再利用できるようになっています。
さらに、これらのデータは構成情報のみのため1カ所に集約して管理し、先に述べた各情報レベルの環境へ「配信」するという構成にしています。理由としては将来的には情報レベルのさらなる細分化や、利用技術によって環境を分離する必要が出てくることを想定しているためです(売上集計の業務環境と大規模なモデルを構築する環境では必要な機能・リソースが異なるというようなことを想定しています)。現在は分析者用途ですが将来的にはエンジニアも他プロダクトのメタデータを知りたいというニーズは出てくると考えられるので、エンジニア向けの用途としても想定しています。
終わりに
マネーフォワードにおけるデータ分析に関するワークロードとアーキテクチャを紹介しました。最後にこれからデータ分析のアーキテクチャを検討されている方にお伝えしたいことがあります。
データ分析に関連した業務や職務は細分化し続けています。以前は分析環境といえば専ら分析用データベースがあるという形でしたが、現在ではデータ量が増加し分析手法も多様化して、単一のデータベースでは実現できないユースケースがたくさん出てきています。それらの実現のために多くの機能や複数の環境が求められるように変化してきていると感じています。
一方で環境の増加はメンテナンスコストや技術的負債の増加を招きます(それらを避けるために機能拡張に消極的になるケースもあります)。これらの最適解を見つけるためには、なるべく多くのステークホルダー・関係者と適切にコミュニケーションをとり、正しい意思決定をし続けることが肝要だと考えています。本記事がみなさまのデータ分析に関する業務の一助となれば幸いです。
編集:中薗昴
提供:株式会社Haul
株式会社マネーフォワードの技術スタックをチェック
無料で技術スタックを掲載する
このページをシェア


技術スタック・ツールのデータベースサービス
© 2026 HRBrain, Inc.
技術スタック・ツールのデータベースサービス
© 2026 HRBrain, Inc.